計算機集成制造系統(CIMS)是現代鋼鐵企業提升生產效率、優化資源配置、增強市場競爭力的核心支撐。邯鄲鋼鐵集團(以下簡稱“邯鋼”)作為國內重要的鋼鐵生產基地,其CIMS的設計與實施,尤其是數據處理環節,構成了整個系統高效、可靠運行的基石。本文將聚焦于邯鋼CIMS中數據處理系統的設計理念、架構與具體實施路徑。
一、 數據處理系統的總體設計目標
邯鋼CIMS數據處理系統的設計,旨在打破傳統“信息孤島”,實現從原料采購、生產調度、工藝控制、質量管理到倉儲物流、銷售服務全流程數據的集成、共享與深度利用。其核心目標包括:
- 數據集成化:統一數據標準與接口,整合來自基礎自動化(L1)、過程控制(L2)及企業資源管理(L3)等不同層級、不同格式的海量數據,形成一致、準確的全廠數據視圖。
- 處理實時化:滿足生產現場對關鍵工藝參數(如溫度、壓力、成分)實時監控與快速響應的需求,確保數據采集、傳輸與處理的低延遲。
- 服務智能化:通過對歷史數據與實時數據的分析、挖掘,為生產優化、質量追溯、故障預警、能源管理等提供智能決策支持。
- 系統高可靠:建立完備的數據備份、容災與安全機制,保障生產數據在復雜工業環境下的完整性、可用性與機密性。
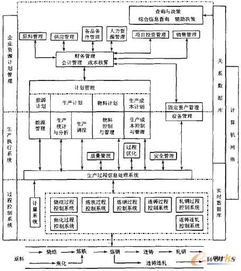
二、 數據處理系統的架構設計
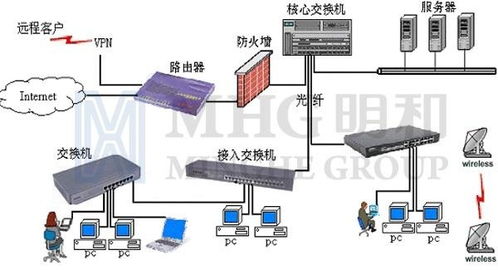
為實現上述目標,邯鋼CIMS采用了分層、分布式的數據處理架構:
- 數據采集層:部署在生產一線的數據采集網關與接口服務器,負責從PLC、DCS、智能儀表、條碼/RFID等設備中自動采集原始數據,并進行初步的濾波、校驗與格式標準化,形成統一的實時數據流。
- 數據集成與存儲層:構建了企業級實時數據庫與關系數據庫雙核心的存儲體系。實時數據庫用于高效存儲和快速訪問帶時間戳的過程數據;關系數據庫則用于存儲生產訂單、質量檢驗、設備檔案等結構化業務數據。兩者通過數據總線進行同步與關聯。
- 數據處理與計算層:該層部署了數據清洗、轉換、加載(ETL)工具以及流式計算引擎。它負責對原始數據進行更深層次的清洗、整合、歸檔,并運行關鍵性能指標(KPI)計算、統計過程控制(SPC)分析、物料平衡核算等核心業務邏輯。
- 數據服務與應用層:以數據倉庫和數據集市為基礎,通過統一的API接口或數據服務平臺,向MES(制造執行系統)、ERP(企業資源計劃)、質量管理系統、設備管理系統等上層應用提供標準、可靠的數據服務,支撐各類業務分析與決策。
三、 關鍵實施策略與技術要點
在具體實施過程中,邯鋼重點關注了以下環節:
- 統一數據編碼與標準:在項目初期,即制定了覆蓋物料、設備、工藝、人員等全要素的企業數據編碼規范,這是實現數據集成與共享的前提。
- 構建高性能數據通道:采用工業以太網與OPC UA等開放協議,建設了高速、穩定的廠級數據網絡,確保海量實時數據能夠無阻塞傳輸。
- 實施漸進式數據遷移:面對龐大的歷史數據,采取“新舊系統并行、分階段遷移”的策略,先確保實時生產數據的平穩接入,再逐步遷移歷史歸檔數據,最大限度降低對現有生產的影響。
- 強化數據質量管理:建立了貫穿數據全生命周期的質量管控規則,包括源頭校驗、過程監控與事后審計,并利用數據質量工具定期評估與修復問題數據,確保“數據可信”。
- 開發主題分析模型:針對鋼鐵生產的特點,開發了面向“煉鐵-煉鋼-連鑄-熱軋-冷軋”全流程的物料跟蹤、質量追溯、能源消耗、成本核算等主題數據分析模型,將數據轉化為 actionable insights(可執行的洞見)。
四、 實施成效與展望
通過系統化的設計與實施,邯鋼CIMS數據處理系統取得了顯著成效:生產指令下達至反饋的周期大幅縮短;關鍵工序的質量數據在線監控率達到100%,質量異議追溯時間從數天縮短至數小時;基于數據的能效分析與優化,實現了顯著的節能降耗。
隨著工業互聯網、大數據與人工智能技術的深度融合,邯鋼的數據處理系統將進一步向云端協同、邊緣智能、預測性維護等方向演進,持續驅動鋼鐵制造向數字化、網絡化、智能化轉型升級,夯實企業高質量發展的數據基石。